LNPU: Sparse DNN Learning Processor
본문
Overview
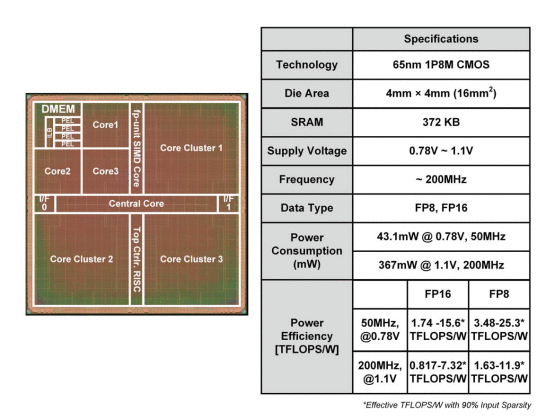
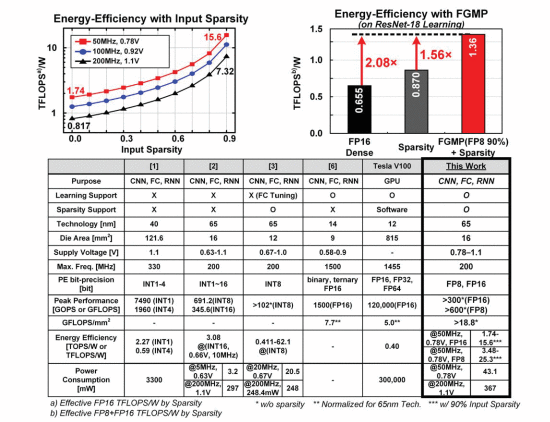
Recently, deep neural network (DNN) hardware accelerators have been reported for energy-efficient deep learning (DL) acceleration [1-6]. Most prior DNN inference accelerators are trained in the cloud using public datasets; parameters are then downloaded to implement AI [1-5]. However, local DNN learning with domain-specific and private data is required meet various user preferences on edge or mobile devices. Since edge and mobile devices contain only limited computation capability with battery power, an energy-efficient DNN learning processor is necessary. Only [6] supported on-chip DNN learning, but it was not energy-efficient, as it did not utilize sparsity which represents 37%-61% of the inputs for various CNNs, such as VGG16, AlexNet and ResNet-18, as shown in Fig. 7.7.1. Although [3-5] utilized the sparsity, they only considered the inference phase with inter-channel accumulation in Fig. 7.7.1, and did not support intra-channel accumulation for the weight-gradient generation (WG) step of the learning phase. Also, [6] adopted FP16, but it was not energy optimal because FP8 is enough for many input operands with 4× less energy than FP16.

Features
- Fine-grained Mixed Precision
- Fully Reconfigurable Sparse
- DL Accelerator FP8/FP16 Mixed Operation
Related Papers
- ISSCC 2019 [pdf]
- 이전글GANPU: Multi-DNN Training Processor for GANs 19.02.08
- 다음글CNPU: Mobile Deep RL Accelerator 19.02.08